Нарешті,SEO-компанія, яка працює на результат
(Від 0 до 1 000 продажів на місяць. Як вам таке?)
- Відновіть втрачені позиції
- Отримайте більше органічного трафіку
- Підвищте обсяги продажів










Інші SEO-агенції багато обіцяють – ми ж маємо реальні приклади результатів
У середньому, ми допомогли клієнтам отримати 780% прибутку від інвестицій.
А ще був випадок, коли ми допомогли клієнту збільшити кількість кліків від 0 до 6 600 на день.
Не вірите? Подивіться самі:

Для нас важливий ваш довгостроковий успіх, а не короткочасні стрибки у ранжуваннях
Не важливо, чи у вас новий сайт і ви хочете почати отримувати тисячі відвідувачів за місяць, чи ви на ринку вже десятиліття, але раптово втратили частину трафіку – наша SEO-компанія допоможе вам залучити якісний трафік за допомогою довгострокової стратегії з оптимізації, створеної для вашого бізнесу.
Сайт вашого бізнесу містить тисячі сторінок чи приносить мільйонні доходи? Наша SEO-компанія допоможе вам оптимізувати кожну сторінку для органічного пошуку і зайняти провідні позиції на ринку.
Ефективне SEO починається з аналізу фактів, а не припущень. Перед тим, як розпочати роботу над проєктом, наша компанія з пошукової оптимізації проведе детальне дослідження, щоб виявити найкращі ключові слова і сформувати дієву стратегію для *вашої* ніші.
Ми розробимо потужну стратегію з побудови зворотних посилань, завдяки якій на ваш контент посилатимуться якісні сайти. Так зросте авторитетність вашого сайту, а отже і ранжування.
Хочете привабити користувачів з інших країн? Ми допоможемо розширити вашу видимість і оптимізувати сайт для різних країн та мов.
Отримайте детальний SEO-аудит вашого сайту і дізнайтесь, що треба зробити, щоб підняти ваші позиції від “як наче взагалі не ранжуємось” до першої сторінки в Google.
Ваш сайт потрапив під санкції чи апдейт Google? Наша SEO-агенція вияснить, що саме пішло не так і як відновити позиції. ASAP.
У якій сфері ви прагнете бути лідером?
Наша SEO-компанія має досвід співпраці з усіма видами бізнесів, які тільки можна уявити – від молодих стартапів до компаній, що входять до рейтингів Fortune 500 та Inc 5 000.


Збільште свій щомісячний дохід та дайте старт серйозному зростанню з ефективною індивідуальною стратегією з SEO-просування.

Перевершіть конкурентів і розширте клієнтську базу, незалежно від вашої спеціалізації.

Отримайте більше трафіку, потенційних клієнтів та продажів у сфері нерухомості не витрачаючись на рекламу.

Покращте свою видимість у пошукових результатах – і отримайте більше трафіку – з SEO-стратегією, створеною спеціально для вашої страхової компанії.

Досягніть вищих позицій у пошукових системах і завоюйте увагу відвідувачів ваших конкурентів без необхідності роздувати бюджет на маркетинг.

Зарекомендуйте себе лідером ринку й отримайте більше контрактів за допомогою збільшення показників трафіку й кількості потенційних клієнтів.
Чим ми відрізняємось від інших SEO-агенцій?
Ми розпочинаємо співпрацю з компаніями тільки тоді, коли ми на 100% впевнені, що можемо досягти необхідних результатів.
Заплануйте безплатну консультацію (яка ні до чого вас не зобов’язує!) і дізнайтесь, чи може наша SEO-компанія досягти тих результатів, які *вам* необхідні.
Усі ті результати досягнуті завдяки чіткому підходу, заснованому на аналізі даних
На жаль, в SEO не існує магії. І хоча наші клієнти, буває, порівнюють нас з магами, за нашими результатами стоїть чіткий підхід:
Ми збираємо й аналізуємо 50-100 груп ключових слів та понад 300 різноманітних факторів, щоб сформувати стратегію, яка буде залучати трафік і збільшувати вашу рентабельність.
Залежно від ваших цілей і потреб, ми зберемо команду SEO-спеціалістів з ґрунтовним розумінням різних SEO-процесів, щоб забезпечити успіх вашої компанії.
Далі ми створимо індивідуальний план просування для вашого бізнесу – пропишемо конкретні кроки, які треба зробити для досягнення ваших цілей.
Тепер час діяти! Ми заплануємо щотижневі зустрічі для обговорення прогресу і, за необхідності, внесення змін у ваш SEO-план.
Ми досягаємо результатів завдяки злагодженому робочому процесу та використанню даних
Ми знаємо, що ваша рентабельність – це наш найважливіший показник. (Бо ж який сенс у всьому тому трафіку, якщо він не перетворюється в продажі?)
Хочете дізнатись, чи зможемо ми досягнути кращих показників для *вашого* бізнесу? Отримайте відповідь на безплатній консультації з нашими спеціалістами.
Зріст рентабельності проєкту у сфері SaaS
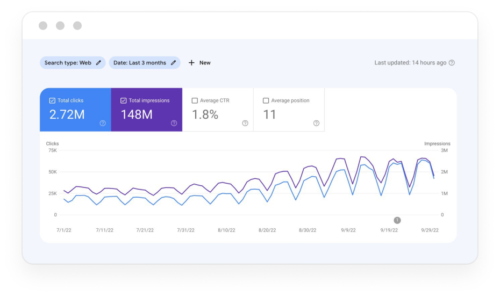
Клієнти працюють з нами в середньому протягом 3 років – і це не безпідставно
Читати більше відгуків
Ми співпрацювали з SeoProfy над складним проектом у висококонкурентній галузі, і ми були цілком задоволені результатами.
Ми раді запропонувати їх як дуже здібну та відповідальну команду, яка добре обізнана зі станом SEO та може досягти виняткових результатів.


Завдяки роботі SeoProfy компанія досягла в середньому понад 1 000 нових продажів на місяць.
Команда працює швидко і прозоро та зосереджується на даних і дослідженнях при виконанні плану, що призводить до успішного партнерства з клієнтом.


Що мені найбільше сподобалося, так це те, що вони перевершили наші очікування.
Вони допомогли нам скласти стратегію на самому початку і вийти в топ за нашими основними ключовими словами, в результаті чого весь трафік виріс і продовжує зростати


Нас вражає сама якість роботи та процесів управління кампанією та проектами, а також їх завершення.
Звіт, наданий SeoProfy, був детальним і ґрунтовним. Команда надає якісні результати вчасно, співпрацюючи з внутрішньою командою на кожному кроці. Вони працьовиті та орієнтовані на деталі.


Їх здатність виконувати роботу вчасно та величезний досвід у сфері SEO та контент-маркетингу вразили нас.
SeoProfy досягла поставлених цілей. Вони змогли підвищити рейтинг компанії в Google. Їх чуйність значною мірою сприяла успіху співпраці.
Інші SEO-агенції використовують лише Ahrefs і Screaming Frog
Ми ж створили власні інструменти, щоб заповнити прогалини у популярних сервісах і впевнитись, що ваші інвестиції принесуть вам приголомшливі прибутки.
Зазирніть в арсенал інструментів, які використовує наша SEO-компанія для досягнення результатів, які хочеться відсвяткувати з келихом шампанського. І так, ми розробили їх власноруч!
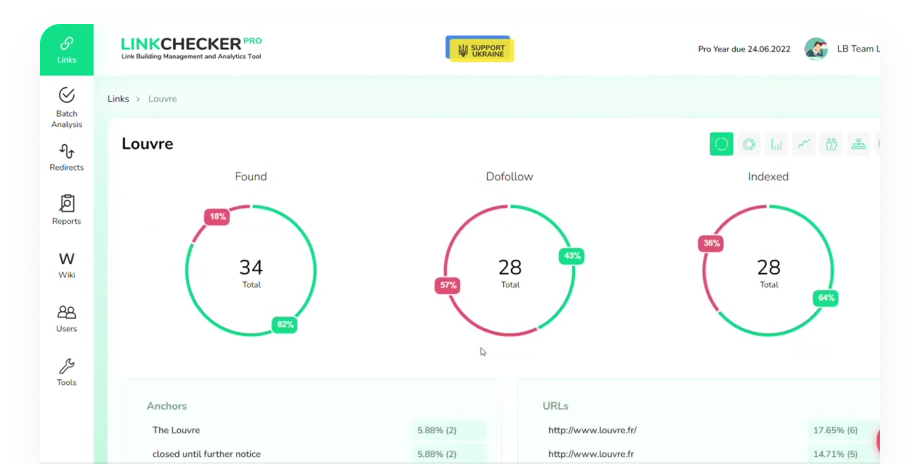
Моніторить і аналізує ваші зворотні посилання (щоб перевірити, чи не погіршують якісь із них ваші показники).
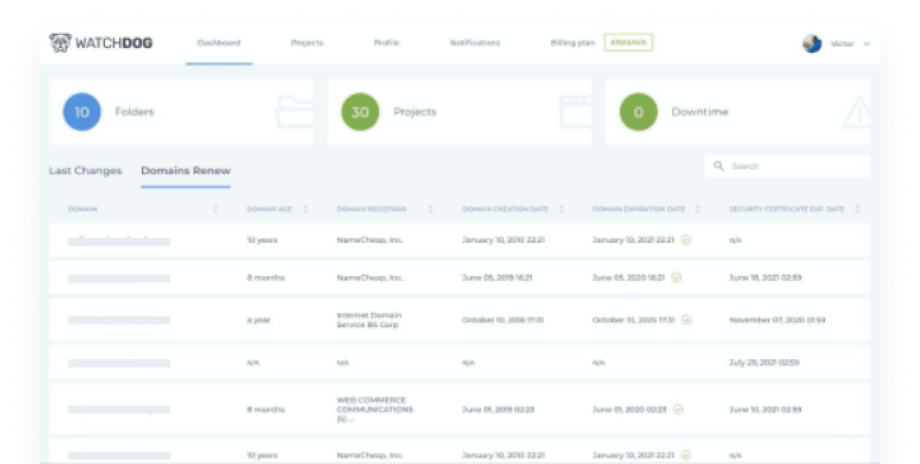
Автоматично відстежує зміни на сайті та перевіряє статус доменів.
Формуємо команду, яка відповідає цінностям SeoProfy
Ви заслуговуєте на більше, ніж безладна команда, перевантажена завданнями з десятків різних проєктів. Ви заслуговуєте на команду, яка працює за чітким планом і для якої ви будете у центрі уваги – і це саме те, що ви отримаєте в нашій SEO-компанії.
Залежно від ваших потреб та цілей, на ваш проєкт будуть підібрані професіонали з високим рівнем експертності у різних сферах пошукової оптимізації й просування сайтів. Наші SEO-спеціалісти слідуватимуть чіткому плану для ефективного і своєчасного виконання задач.
А хто ж стоїть за плануванням та контролює весь процес? Знайомтесь – наша команда менеджерів:









Набридли SEO-агенції, які дають пусті обіцянки, але не показують результатів?
Так казали більшість наших клієнтів… до того, як почали працювати з нами.
У нашій SEO-компанії не роблять обіцянок, яких не можуть дотриматися. Заплануйте безплатну консультацію зараз і дізнайтесь, чи зможе наша SEO-агенція досягнути необхідних вам результатів.
Познайомтеся з новими членами вашої маркетингової команди


Наша команда складається з більш ніж 200 SEO-спеціалістів, які разом мають 1 000 років досвіду роботи на іноземних ринках, у тому числі з клієнтами з США, Канади, Великобританії, Австралії, Нової Зеландії, Європи, Азії та Латинської Америки.
Ми працюємо з компаніями з 45 країн, 12 мовами. Тож, де б не знаходилась ваша компанія – і який би ринок ви не хотіли покорити наступним – наша міжнародна SEO-агенція задовольнить усі ваші потреби.
Ми збільшили обсяги трафіку, кількість потенційних клієнтів і продажів для клієнтів у висококонкурентних нішах (як-от автострахування, фінансові технології, дейтинг, геймінг, освітні послуги, фармацевтика, нерухомість, ІТ тощо).
Не вірите нам? Погляньте на реальні приклади нашої роботи, щоб переконатись у результативності наших підходів.
Тож, побачивши, на що здатна наша SEO-агенція, ви, мабуть, задумались…
Що ж, відповідь на це питання досить проста: якщо ми не впевнені на всі сто, що зможемо досягнути тих результатів, які ви хочете отримати, то не візьмемось за ваш проєкт.
Бо ж ми тримаємо за ціль довгострокову співпрацю з кожним нашим клієнтом.
(Наші клієнти не просто так працюють з нами протягом щонайменше 1,5-2, а то й 10 років.)
Якщо ми все ж почнемо працювати з вами, то створимо реалістичну SEO-стратегію.
І ще одна річ, яку важливо знати про нас…
Скажемо так: якщо у нас не виходить вкластися у дедлайн – або ж щось не спрацьовує, як планувалося – то ми вам повідомимо. Одразу.

Мали невдалий досвід з іншими агенціями? Багато наших клієнтів розповідали схожі історії
Але наша агенція з пошукової оптимізації не така, як головні злодії цих історій. Правда.
| Інші SEO-агенства |
Так, це ми!
|
|---|---|
Дають багато гучних обіцянок і гарантій, які вони не можуть виконати |
Беруть у роботу тільки ті проєкти, для яких дійсно можуть досягти необхідних результатів |
Пропонують типові рішення (які призводять до таких собі результатів) |
Виділяють час на вивчення вашого бізнесу, ваших цілей і потреб, а потім створюють індивідуальну стратегію, націлену на підвищення прибутковості |
Члени команди розриваються між мільйоном проєктів (через що допускаються протермінування і помилки) |
Ефективно планують і розподіляють задачі між спеціалістами, щоб забезпечити ефективність і своєчасність їх виконання |
Можуть не сказати, що обрана стратегія не працює… чи що задачу не виходить виконати |
Будуть повністю прозорими щодо досягнення цілей і дедлайнів (і повідомлять вам, якщо щось піде не за планом) |
Орієнтуються на швидкі результати та кількість, а не якість |
Прагнуть досягти довготривалого успіху в SEO для вашого сайту і знають, що якість трафіку набагато важливіша, ніж його кількість |
Вимірюють успіх за ранжуваннями та органічним трафіком |
Знають, що рентабельність – це все ж найважливіший показник |
Пропонують типові відносини у форматі “продавець-покупець” |
Стають продовженням вашої маркетингової команди (щиро зацікавленими у вашому успіху) |
Просто приймають вказівки (тож ви й ваша команда залишаєтесь відповідальними за створення стратегії) |
Створюють ефективну стратегію, орієнтовану на результат (що чітко видно в наших практичних кейсах) |
Беруть ваші гроші й аутсорсять задачі рандомним фрилансерам (привіт, шахраї!) |
Уважно обирають найкращих спеціалістів з вузькопрофільними знаннями й досвідом, які ідеально підійдуть для вашого проєкту |
Маєте питання? У нас є відповіді
У середньому, наші клієнти починають бачити перші результати від SEO протягом 4-6 місяців.
Однак, якщо ви працюєте у висококонкурентній сфері, для цього може знадобитися 1-2 роки.
Оскільки ми створюємо індивідуальні стратегії для кожного сайту, цей час буде залежати від декількох факторів, наприклад:
- вік та авторитетність вашого сайту;
- структура й дизайн сайту;
- стан вашої внутрішньої й зовнішньої оптимізації;
- санкції, що можуть знижувати ваші позиції.
Якщо коротко: залежить від ситуації!
Ми завжди розпочинаємо з детального SEO-аудиту. Аналізуємо все: від швидкості сторінок та мобільної оптимізації до застарілого контенту та прогалин у заповненості сайту.
Після цього, ми збираємо й аналізуємо найкращі ключові слова для вашого вебсайту й створюємо стратегію, яка відповідає вашим індивідуальним потребам і цілям.
Нам не подобається термін “аутсорс”, бо він асоціюється з нижчою якістю. Ми підбираємо найкращих спеціалістів для вашого проєкту. Крапка.
Як саме?
Для деяких проєктів ми ретельно підбираємо і наймаємо спеціалістів, які будуть вкладати весь свій робочий час у роботу з одним клієнтом, для деяких – обираємо експертів з власної команди, які мають необхідний досвід та знання і яким ми повністю довіряємо.
Звісно! SeoProfy має досвід співпраці з декількома корпораціями, які входять до рейтингів Fortune 500 та Inc 1 000. Це великі компанії, про які ви точно чули (але ми не можемо вам розповісти детальніше через угоди про нерозголошення).
Так! Лінкбілдинг – це один із головних напрямків нашої діяльності.
Наша SEO-агенція роками розбудовувала й підтримувала зв’язки з іншими бізнесами, щоб допомогти клієнтам отримати якісні посилання, що призводять до зросту показників трафіку.
Досить витрачати гроші на SEO-агенції, які дають багато обіцянок, але показують мало результатів
Замовте безкоштовну консультацію з нашою SEO-фірмою зараз і розкрийте потенціал вашого сайту.




